Hace poco descubrí una entrevista muy interesante entre Allen Holub y Robert “Uncle Bob” Martin. Quizá el segundo sea más conocido por Clean Code o la saga de libros Clean, pero Allen cuenta con la experiencia necesaria para darle muy buen curso a la conversación con preguntas, acotaciones y puntos de vista que hacen que la media hora pase sin que nos demos cuenta.
En la entrevista se tocan puntos como: – Lo que debemos hacer si nos interesa evolucionar como desarrolladores de software – Libros que deberíamos leer y la importancia de los fundamentos que encontraremos en estos – La práctica hace al maestro, pero podría tomar algo de tiempo – Liderazgo y su impacto en el aprendizaje y productividad del equipo – El trabajo remoto y la necesidad de las interacciones personales – Puedes invertir tiempo enseñando y te irá bien con eso, pero tienes que aceptar que no vas a convencer a todo el equipo – Disciplina, estándares y ética
Si bien, es cierto ENIAC es reconocida como la primera computadora (1945), un año antes ya existía la Harvard Mark I, que incluía el uso de tarjetas perforadas para su programación (técnica que se usó por muchos años) y soporte a ejecución multipropósito (a la fecha, cualquier computadora personal cumple ese objetivo)
Entonces, si ENIAC se programaba por medio de circuitos (lo cual incrementaba la complejidad de entendimiento y uso) e inicialmente ejecutaba cálculos con objetivos armamentistas ¿Por qué cuando se habla de Historia de la Computación, se le da tanta relevancia?
Yo creo que no solo tuvo que ver su importancia e impacto en objetivos armamentistas de la época, sino también su velocidad de ejecución. ENIAC realizaba cálculos matemáticos en menos de 1 segundo, mientras que Mark I podría tardar hasta 15 segundos en mostrar el resultado de una simple operación aritmética.
Queda decir, que si la velocidad de ejecución siempre jugó un papel importante ¿Por qué no darle la relevancia del caso, incluso desde etapas muy tempranas?
La respuesta puede parecer obvia, pero vale la pena la aclaración, NO.
Hace pocas horas, usuarios de HBO Max recibieron un mensaje que, si no conoces de tecnología, puede que no lo entiendas. El hecho es simple, se ejecutó una prueba sin verificar los destinatarios.
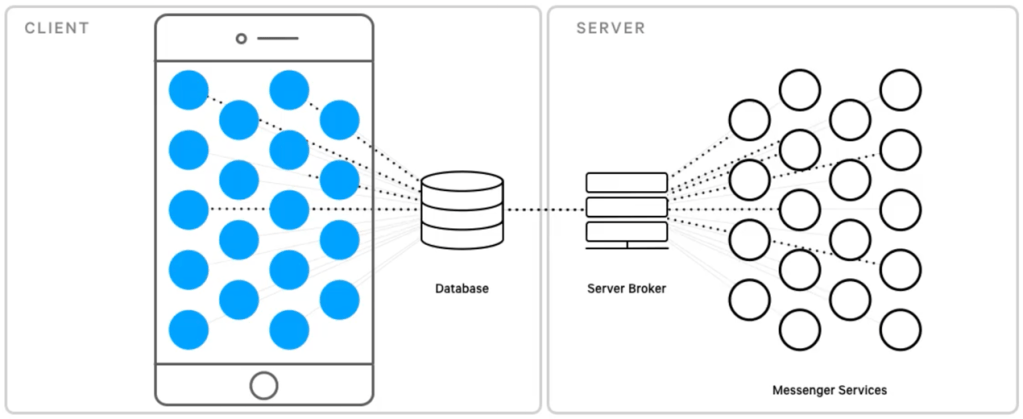
Mientras leo la publicación, encuentro que se habla de una plataforma de mensajería en vez de un app convencional. Creo que una visión de este tipo es muy importante si es que queremos dar un gran paso en el diseño de nuestro software. No está de más decir que una de las barreras que encontraremos regularmente, será el poco entendimiento de la diferencia entre plataforma, aplicación y herramienta.
Si bien es cierto la visión es muy importante, esta debe servir para definir –y abrazar– principios de arquitectura adecuados para cumplir con el sueño esperado.
1. Usar el Sistema Operativo
Aquí la clave fue eliminar el código que podía ser reemplazado por alguna funcionalidad del sistema operativo. Si este no lo hacía bien, pues se decidió construir una librería en lenguaje C, la cual estoy seguro será reutilizada en la versión para Android que lanzarán en algún momento.
Este tipo de estrategias es muy importante porque es una forma concreta de apoyar a la eliminación de código innecesario, el cual muchas veces se refleja en frameworks o intermediarios que a pesar de ayudarnos –bajo la perspectiva de programador– hace que la aplicación sea más lenta.
2. Usar SQLite
De lo que le he revisado no queda claro si antes utilizaban SQLite, pero en esta nueva versión toda la información que se utilice pasará primero por la base de datos local. Esto podría significar que no hay invocación directa a servicios pues la comunicación sería similar a lo que se ve en una aplicación monolítica convencional.
Queda mencionar que el gestor que se utiliza es una versión mejorada de SQLite. La diferencia radica en el soporte a stored procedures y de paso se promueve la reutilización.
A nivel de estructura de datos, lo que se ha buscado en esta nueva versión es eliminar los diseños complejos y reflejar en una tabla lo que se necesita para poder mostrarla en la interfaz de usuario. Estoy seguro de que son tablas con información redundante. Es decir, menos normalización, más velocidad 🙂
3. Reutilizar la Interfaz de Usuario
Cuando los amigos de Facebook revisaron el código fuente encontraron cosas interesantes, el caso que ponen como ejemplo es la cantidad de componentes visuales que representaban un mismo set de datos. Por ejemplo, se encontraron componentes diferentes para la presentación horizontal y la presentación vertical. Hasta aquí todo podría parecer natural, pero creo que encontrar 40 vistas para representar un mismo set de datos es un error que no se puede volver a cometer.
Lo que algunos hacemos en este tipo de casos es quedarnos con la vista que pueda ser tomada como base de reutilización o bueno, en el peor de los casos tenemos que crear un nuevo componente. Eso sí, en casi todos los casos iremos eliminando vistas innecesarias y por ende, código innecesario.
4. Usar –más– el servidor
Si bien es cierto estamos en la época de las aplicaciones que procesan información por medio de servicios o alguna de sus variantes, en este caso se aprovecha el procesamiento local (gracias a SQLite) y se trabaja con un componente que hace las veces de sincronizador de información. Lo interesante es que este componente está alojado principalmente en el servidor, lo cual me recuerda al concepto de publicador/suscriptor. Ojo que estoy tratando de simplificar conceptos, estoy seguro de que hay más trabajo por detrás 🙂
Comentarios
Me parece muy interesante de que Facebook invierta en un proceso de ingeniería que para muchos podría ser considerado como radical y que “no se puede hacer drásticamente pues no representará valor para el negocio”. Esto lo coloco entre comillas pues es una respuesta que encuentro regularmente cuando converso con desarrolladores de software que trabajan en proyectos en diferentes rubros.
Por otro lado, está de más mencionar que los beneficios hablan por sí solos, pero creo que es consecuencia de haber esperado tanto tiempo para poner una suerte de termómetro en el desarrollo que venían realizando. Estoy seguro de que hubo al menos una reunión en la que comentaba lo difícil que era seguir avanzando con el desarrollo y que lo mejor era rehacer algunas –o muchas– cosas si se buscaba mayor escalabilidad.
Con respecto a algunas consideraciones técnicas del trabajo realizado, la reducción de código es una consecuencia directa de la eliminación de código muerto y de haber descartado funcionalidades que eran menos utilizadas. También hay que resaltar la importancia de las automatización de pruebas unitarias y la respectiva cobertura, una vez escuché que en Facebook buscaban una cobertura del 100% y en este caso solo mencionan que el componente de sincronización cumple con ese objetivo.
Ahora, yendo un poco más atrás y revisando la presentación del proyecto en una sesión del F8 del año pasado, se menciona que el objetivo es contar con una nueva versión tanto para iOS como para Android, así que en cualquier momento tendremos mayores novedades 🙂
Si trabajamos en el mundo de la tecnología, ya nos debe haber pasado –o escuchado– de que el sistema se cayó por un cambio mal realizado. A veces nos pasa que mientras arreglamos una cosa malogramos otras. Mucho cuidado con los círculos viciosos.
Estas situaciones me recuerdan las veces que juego [Jenga] con mis amigos. Y es que, de empezar con una mala estrategia, llegado un punto, cada turno se vuelve emocionante pues nadie quiere tumbar la torre de madera.
Si en los proyectos de tecnología empezamos sin una estrategia técnica adecuada, muchas veces tendremos dolores de cabeza en el futuro. Sin ir muy lejos, muchas decisiones técnicas son pasadas por alto a consecuencia de “ahorrar”, “lo arreglamos después”, “las cosas siempre fueron así” o la necesidad de solucionar problemas rápidamente sin entender por completo las implicancias del mismo o incluso sin entender la solución.
Sinceramente creo que pasar por este tipo de situaciones nos hacen crecer profesionalmente. Sin ir muy lejos, con el paso del tiempo he descubierto que ya no me gustan algunas soluciones que hice en proyectos anteriores, la idea es ir descubriendo nuevas formas y cuestionar nuestro trabajo. Creo que deberíamos ser los primeros en hacerlo.
Regresando a la analogía, les cuento que conversando con muchos amigos o con las personas que me entrevistaban mientras buscaba trabajo, he confirmado mi teoría; todos hemos tenido una torre de Jenga que se ha derrumbado al menos una vez en nuestros sistemas. A veces nos reímos de eso y otras nos avergüenza, pero lo más importante es que hemos tenido la capacidad de aprender y jugar sabiamente.
Hay una persona que puede resolver los problemas “difíciles” y algunas veces ese es su trabajo principal. En algunos casos su rol o título es “el especialista”
La gestión de versiones es pobre o nula.
Los pases a producción se ejecutan manualmente.
Las pruebas se hacen “a mano”
La documentación no está actualizada o bueno, no existe.
Tal como dije al empezar con este post, puede que nos hayan pasado estas cosas y no hay problema con ello. Lo que sí creo es que sería irresponsable no hacer algo al respecto para que esto no nos vuelva a ocurrir.
¿Qué es lo que podemos hacer?
Puede que este sea –o suene– un trabajo complicado pero no es imposible. Los factores de éxito más importante tienen que ver con la determinación para resolver los problemas y el tiempo necesario para empezar con este tipo de trabajos.
A pesar de ello, he dividido esta estrategia en tres etapas.
#1: Orden
Si no cuentan con una gestión de versiones adecuadao no han explorado ese camino, pues Git sobre GitHub es un excelente punto de partida. No se compliquen la vida pensando en qué archivos agregar al gestor de versiones, la depuración será parte del trabajo a realizar. Si no están familiarizados, aquí algunas referencias a tener en cuenta:
Identifiquen el código innecesario, para no perder mucho tiempo en este paso, tienen que trabajar con herramientas como [SonarQube]. En mi publicación de [código muerto] encontrarán más detalle al respecto.
Limpien su código fuente aprovechando la información encontrada en el paso anterior. Como mencioné en [código muerto], un buen calentamiento es comenzar por esas carpetas y archivos que nadie usa. Descubrirán que es un trabajo divertido y que en el tiempo resulta motivador ver cómo el código se va limpiando de a pocos y claro, los indicadores de SonarQube van reflejando el resultado de nuestro esfuerzo.
Busquen que los especialistas en resolver problemas sean los primeros candidatos a ser referentes técnicos. Estoy seguro de que encontrarán de que hay experiencia que no está correctamente enfocada. Los especialistas podrán ayudar a identificar y/o eliminar esos elementos muertos y mejor aún, cumplir con labores más interesantes.
Ojo que esta actividad también nos servirá para confirmar si nuestros especialistas están preparados para dar el próximo paso o quizá es que no están interesados en hacerlo.
Hablemos de automatizando. Un paso muy importante es engranar el desarrollo con un servidor de automatización y uno de los más populares es [Jenkins]. Lo mínimo necesario es implementar un flujo de [Integración Continua] y si todo marcha bien, ir pensando en la [Entrega Continua]. No se apuren en cumplir todas las recomendaciones que puedan encontrar en la web, con el paso de cada de actividad descubrirán qué paso agregar u omitir en el flujo de automatización.
Identifiquen el código de las funcionalidades más importantes para el negocio. Aquí es donde los referentes técnicos nos darán una mano o en el peor de los casos, confirmarán que alguno de ellos solo se había orientado a resolver problema sin entender las causas o impacto en el negocio. Si esto ocurre no se preocupen, siempre habrán cosas por mejorar pero dependeremos mucho de la actitud de los involucrados.
Automaticen sus pruebas. Es posible que hayan escuchado que es un trabajo interminable o que pone en riesgo las fechas comprometidas pero hay que sincerar las cosas, en un primer intento no podremos automatizar todo. Aquí es donde veremos la importancia de haber identificado las funcionalidades más importantes. La primera versión de esta automatización no tiene que ser perfecta pero debe existir alguna forma sencilla de validar las más importantes. Lo más importante radica en que el equipo decida el número mínimo de pruebas a automatizar. Aquí dos consideraciones a tener en cuenta:
Si no tienen el tiempo necesario, pueden empezar con [pruebas unitarias], cuya tecnología dependerá del stack tecnológico con el que cuenten.
Si quieren dar un paso más adelante y están trabajando sobre una plataforma web o servicios REST, pueden realizar pruebas usando [cypress]
Refactoricen, sigan limpiando, midan el avance. Herramientas como [SonarQube] o [New Relic] les darán una serie de pistas que los ayudarán a seguir limpiando el código. No tienen que seguir todas las recomendaciones, la idea es ir mejorando la calidad del código mientras van construyendo nuevas funcionalidades, siempre recordando que las pruebas automatizadas nos indicarán si estamos rompiendo algo que ya funcionaba.
#2: Equipo
Busquen alinear los conocimientos del equipo. Si bien es cierto este es un ideal, lo mínimo esperado es que los especialistas compartan lo necesario para ir cortando dependencias. Lo que necesitamos es tener más jugadores de equipo y de paso confirmar si los especialistas se pueden afirmar como referentes técnicos (una forma de hacerlo es creando espacios donde puedan compartir lo que saben)
Promuevan más reuniones técnicas. La temática puede estar relacionada a un problema, una solución, una técnica de programación, un sistema o una tecnología en particular. Consideren que también podrían invitar a personas de otros equipos o empresas (para compartir algún tema como los mencionados)
Promuevan la capacitación del equipo. Ser autodidactas es bueno, pero si está a nuestro alcance gestionar o solicitar ese capacitaciones para el equipo, es nuestra responsabilidad hacerlo. Estas sesiones deben considerar aspectos prácticos. Para ser claros, toda teoría debe complementarse con un ejemplo que empuje al equipo a escribir código. Aquí unos tópicos que sugiero regularmente:
Programación orientada a objetos
Algoritmos de búsqueda
Teoría de complejidad
Pruebas unitarias
Refactorización
Test Driven Development
Automatización de pruebas
Servidores o servicios de automatización
Evalúen. Esto se debe realizar de manera continua mientras se vaya realizando la capacitación y debe confirmarse con una evaluación final, la cual debe ser con computadora en mano. Con esto confirmarán si el objetivo de la capacitación se ha cumplido.
Definan con el equipo las nuevas reglas del juego. El equipo seguirá desarrollando las funcionalidades requeridas por el negocio pero en adelante debería haber apertura para:
Refactorizar el código existente sin romper las pruebas unitarias ya construidas
Implementar nuevas pruebas unitarias, además de la relacionada a la nueva funcionalidad a construir
Eliminar código muerto
Gestionar la deuda técnica sin ser perfeccionistas
#3: Visión
Hay que tener en cuenta de que estamos trabajando sobre la practica de ir mejorando lo existente mientras seguimos atendiendo la misión del negocio. Esto es lo que ocurre normalmente, no debemos olvidar la visión del negocio y que además esta nos sirve como referencia principal de nuestra visión tecnológica. Lo que he encontrado en algunas situaciones es que también hay mucho trabajo por realizar, aquí algunas consideraciones:
¿Tenemos un diagrama de situación actual? No se preocupen, lo normal es que ese diagrama no exista. La buena noticia dependerá de qué tan bien hayamos seguido la práctica de realizar reuniones técnicas. Si la respuesta es positiva, lo que debe hacer el equipo es dibujar el primer diagrama AS-IS de los sistemas de la empresa. Estas sesiones también servirán para crear una lista de aquellas cosas por refactorizar/mejorar, la cual debe estar relacionada con cada elemento identificado en el diagrama.
Es momento de definir nuestros compromisos técnicos. Lo normal es tener objetivos técnicos (p.e. reducir los errores en 25%) mientras que los compromisos muchas veces se omiten o se consideran implícitos. Lo mejor es aclarar en conjunto aquellos compromisos que en adelante se respetarán por la salud técnica de nuestros sistemas. Aquí una propuesta:
Funcional: Fácil de usar (perspectiva del usuario)
Flexible: Fácil de entender y modificar (perspectiva del desarrollador)
Extensible: Fácil de conectar con otros sistemas (perspectiva del desarrollador y del sistema)
Automatizable: Lo necesario para poder compilar, probar, desplegar y diagnosticar fácilmente.
¿A dónde queremos llegar? El objetivo de esta actividad es obtener un diagrama TO-BE teniendo en cuenta lo siguiente:
Podemos soñar
Debemos considerar que tenemos al menos dos inputs técnicos, el diagrama AS-IS y la lista de cosas por refactorizar/mejorar
Un input adicional –y que no es técnico– es la visión del negocio ¿qué es lo que se está buscando en 3, 5, 10 años? Mientras más información tengamos, mucho mejor
¿Podemos soñar? Claro que sí pero tampoco creamos que de un día a otro conseguiremos arquitecturas como las que promueven Amazon, Netflix, Uber o tantas grandes empresas.
Debemos considerar que en el tiempo nuestra torre se debe transformar en una fortaleza. Lo ideal es derrumbar todo y empezar de nuevo pero eso sí sería soñar en grande.
Seamos realistas. No me malinterpreten, lo que quiero decir es que debemos hacer una comparación entre lo que tenemos y lo que buscamos y sobre eso hagamos un plan que busque eliminar ese gap poco a poco.
Tengamos en cuenta de que cada paso se debe convertir en al menos una meta a cumplir y que cada meta debe ser fácil de medir en un tiempo determinado.
Por otro lado si es que no tenemos opción a reemplazar todo un sistema. Lo que podemos hacer es hacer el reemplazo de aquellos componentes que a veces vale la pena reemplazar por un nuevo desarrollo o por algo que podríamos comprar y modificar. Si esto se puede hacer para varios elementos de un sistema, es un proceso que le he llamado “reemplazo silencioso del sistema”
La deuda siempre existirá y sigamos trabajando con eso. No tenemos que ser perfeccionistas, [la regla del 80-20] siempre ayuda.
Comentarios finales
Lo que he encontrado en algunos equipos es que con el paso del tiempo nos volvemos jugadores expertos de Jenga y la verdad es que eso es algo que no deberíamos buscar. No es saludable.
Lo que también he encontrado es que una definición incorrecta del trabajo a realizar –para atacar la torre de Jenga– hará que no se encuentre o vea el valor de lo que estamos buscando. Parte de esto lo menciono en [la importancia de la arquitectura de un sistema]
Algo muy importante –y obvio para algunos– es que necesitarán más jugadores de equipo y menos jugadores de Jenga.









{kind=link}