Hace poco descubrí una entrevista muy interesante entre Allen Holub y Robert “Uncle Bob” Martin. Quizá el segundo sea más conocido por Clean Code o la saga de libros Clean, pero Allen cuenta con la experiencia necesaria para darle muy buen curso a la conversación con preguntas, acotaciones y puntos de vista que hacen que la media hora pase sin que nos demos cuenta.
En la entrevista se tocan puntos como: – Lo que debemos hacer si nos interesa evolucionar como desarrolladores de software – Libros que deberíamos leer y la importancia de los fundamentos que encontraremos en estos – La práctica hace al maestro, pero podría tomar algo de tiempo – Liderazgo y su impacto en el aprendizaje y productividad del equipo – El trabajo remoto y la necesidad de las interacciones personales – Puedes invertir tiempo enseñando y te irá bien con eso, pero tienes que aceptar que no vas a convencer a todo el equipo – Disciplina, estándares y ética
La respuesta simple es que “hay mucho código por revisar“, y tiene sentido, pues si estamos liberando funcionalidades, sea diaria, semanal o mensualmente, el equipo está escribiendo tanto código como se necesite. Y si además se respeta un procedimiento de construcción adecuado, así se tengan herramientas y/o automatizaciones, se necesitará una validación adicional, y con esto me refiero a la humana.
Ojo, y esto fue mencionado por Fred Brooks hace casi cincuenta años, así se agreguen más personas al proceso, el tiempo siempre jugará en contra o peor, podría incrementarse, sea – y esta es una opinión personal– porque hay reuniones por atender, dudas que resolver o bueno, cosas para ayer.
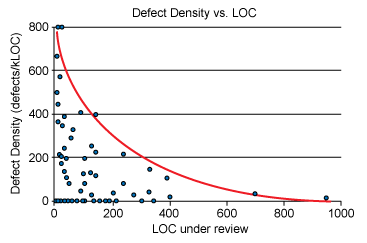
Entonces solo queda afinar el proceso, quizá definir periodos, horarios de revisión, reglas y puntos que prefiero mencionar en otra publicación, pero –para no alargar esto– lo mínimo a considerar es el tamaño del bloque o tamaño del código a revisar.
Ahora, si no tenemos idea al respecto, un estudio –que, por cierto, tiene algunos años, pero su base de investigación es muy interesante– recomienda manejar un rango de revisión que va entre las 200 y las 400 líneas de código y que el proceso como tal, no debería tomar más de una hora.
Ahora, algunos se preguntarán ¿cómo se mide esto?, por suerte se tienen herramientas cada vez más sofisticadas –y también podríamos hablar de ello–, pero aquí el problema no es ni será la herramienta, sino el acuerdo que debe tomar el equipo sobre lo que a veces llamo “el tamaño de la propuesta de cambio“, donde propuesta cambio (asociada al concepto de changeset, pero de eso podemos hablar otro día) refiere al bloque de código asociado a la funcionalidad que queremos incluir en el producto que estamos construyendo.
Personalmente creo –y obviamente puedo estar equivocado– que debería ser uno de los primeros acuerdos que se deben manejar dentro del equipo, caso contrario se afectará la calidad del producto, y aquí debemos recordar que productos digitales que funcionan hay muchos, pero que funcionen bien, ese ya es otro tema.
Si bien, es cierto ENIAC es reconocida como la primera computadora (1945), un año antes ya existía la Harvard Mark I, que incluía el uso de tarjetas perforadas para su programación (técnica que se usó por muchos años) y soporte a ejecución multipropósito (a la fecha, cualquier computadora personal cumple ese objetivo)
Entonces, si ENIAC se programaba por medio de circuitos (lo cual incrementaba la complejidad de entendimiento y uso) e inicialmente ejecutaba cálculos con objetivos armamentistas ¿Por qué cuando se habla de Historia de la Computación, se le da tanta relevancia?
Yo creo que no solo tuvo que ver su importancia e impacto en objetivos armamentistas de la época, sino también su velocidad de ejecución. ENIAC realizaba cálculos matemáticos en menos de 1 segundo, mientras que Mark I podría tardar hasta 15 segundos en mostrar el resultado de una simple operación aritmética.
Queda decir, que si la velocidad de ejecución siempre jugó un papel importante ¿Por qué no darle la relevancia del caso, incluso desde etapas muy tempranas?
Hace casi dos años, postulé a puestos en los que me hacían preguntas de todo tipo, era algo extraño pero como era la primera vez –en años– en la que buscaba conectarme al mundo laboral –y bueno, esos procesos me causaban curiosidad– decidía continuar con las entrevistas,
Me gustaría decir que estoy exagerando, pero dicha entrevista existió (y se repitió en al menos un par de procesos más). Por mi parte no veo inconveniente en responder, pues es un hecho que nadie sabe todo, así que decía la verdad en cada caso. Y bueno, como me gusta conversar, al culminar una de las reuniones, le pregunté al entrevistador la causa de ese nivel de detalle, de eso encontré tres cosas:
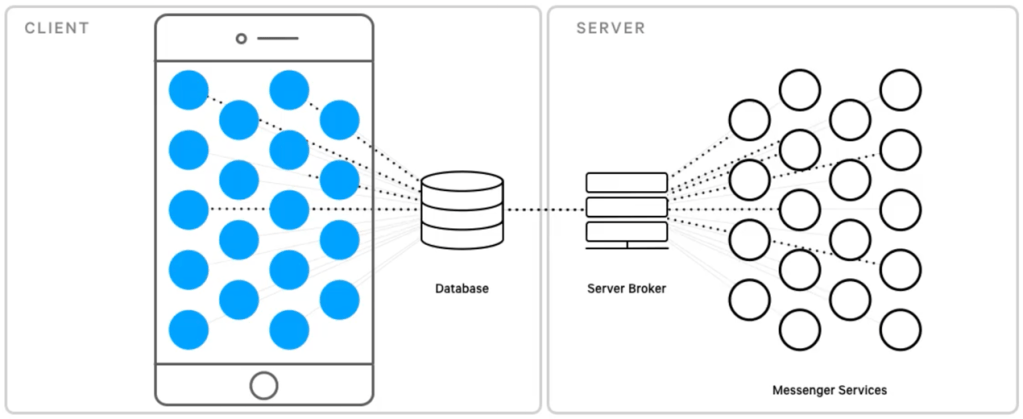
Mientras leo la publicación, encuentro que se habla de una plataforma de mensajería en vez de un app convencional. Creo que una visión de este tipo es muy importante si es que queremos dar un gran paso en el diseño de nuestro software. No está de más decir que una de las barreras que encontraremos regularmente, será el poco entendimiento de la diferencia entre plataforma, aplicación y herramienta.
Si bien es cierto la visión es muy importante, esta debe servir para definir –y abrazar– principios de arquitectura adecuados para cumplir con el sueño esperado.
1. Usar el Sistema Operativo
Aquí la clave fue eliminar el código que podía ser reemplazado por alguna funcionalidad del sistema operativo. Si este no lo hacía bien, pues se decidió construir una librería en lenguaje C, la cual estoy seguro será reutilizada en la versión para Android que lanzarán en algún momento.
Este tipo de estrategias es muy importante porque es una forma concreta de apoyar a la eliminación de código innecesario, el cual muchas veces se refleja en frameworks o intermediarios que a pesar de ayudarnos –bajo la perspectiva de programador– hace que la aplicación sea más lenta.
2. Usar SQLite
De lo que le he revisado no queda claro si antes utilizaban SQLite, pero en esta nueva versión toda la información que se utilice pasará primero por la base de datos local. Esto podría significar que no hay invocación directa a servicios pues la comunicación sería similar a lo que se ve en una aplicación monolítica convencional.
Queda mencionar que el gestor que se utiliza es una versión mejorada de SQLite. La diferencia radica en el soporte a stored procedures y de paso se promueve la reutilización.
A nivel de estructura de datos, lo que se ha buscado en esta nueva versión es eliminar los diseños complejos y reflejar en una tabla lo que se necesita para poder mostrarla en la interfaz de usuario. Estoy seguro de que son tablas con información redundante. Es decir, menos normalización, más velocidad 🙂
3. Reutilizar la Interfaz de Usuario
Cuando los amigos de Facebook revisaron el código fuente encontraron cosas interesantes, el caso que ponen como ejemplo es la cantidad de componentes visuales que representaban un mismo set de datos. Por ejemplo, se encontraron componentes diferentes para la presentación horizontal y la presentación vertical. Hasta aquí todo podría parecer natural, pero creo que encontrar 40 vistas para representar un mismo set de datos es un error que no se puede volver a cometer.
Lo que algunos hacemos en este tipo de casos es quedarnos con la vista que pueda ser tomada como base de reutilización o bueno, en el peor de los casos tenemos que crear un nuevo componente. Eso sí, en casi todos los casos iremos eliminando vistas innecesarias y por ende, código innecesario.
4. Usar –más– el servidor
Si bien es cierto estamos en la época de las aplicaciones que procesan información por medio de servicios o alguna de sus variantes, en este caso se aprovecha el procesamiento local (gracias a SQLite) y se trabaja con un componente que hace las veces de sincronizador de información. Lo interesante es que este componente está alojado principalmente en el servidor, lo cual me recuerda al concepto de publicador/suscriptor. Ojo que estoy tratando de simplificar conceptos, estoy seguro de que hay más trabajo por detrás 🙂
Comentarios
Me parece muy interesante de que Facebook invierta en un proceso de ingeniería que para muchos podría ser considerado como radical y que “no se puede hacer drásticamente pues no representará valor para el negocio”. Esto lo coloco entre comillas pues es una respuesta que encuentro regularmente cuando converso con desarrolladores de software que trabajan en proyectos en diferentes rubros.
Por otro lado, está de más mencionar que los beneficios hablan por sí solos, pero creo que es consecuencia de haber esperado tanto tiempo para poner una suerte de termómetro en el desarrollo que venían realizando. Estoy seguro de que hubo al menos una reunión en la que comentaba lo difícil que era seguir avanzando con el desarrollo y que lo mejor era rehacer algunas –o muchas– cosas si se buscaba mayor escalabilidad.
Con respecto a algunas consideraciones técnicas del trabajo realizado, la reducción de código es una consecuencia directa de la eliminación de código muerto y de haber descartado funcionalidades que eran menos utilizadas. También hay que resaltar la importancia de las automatización de pruebas unitarias y la respectiva cobertura, una vez escuché que en Facebook buscaban una cobertura del 100% y en este caso solo mencionan que el componente de sincronización cumple con ese objetivo.
Ahora, yendo un poco más atrás y revisando la presentación del proyecto en una sesión del F8 del año pasado, se menciona que el objetivo es contar con una nueva versión tanto para iOS como para Android, así que en cualquier momento tendremos mayores novedades 🙂