Una de las anécdotas más comunes de un proyecto de software es que siempre hay una clase o una función que será recordada por el número de líneas que esta tuvo. Estoy seguro de que al menos una vez hemos escuchado:
“No toques esa clase, tiene como 1000 líneas de código”
Developer anónimo
Este es un dato particular de acuerdo a los proyectos en los que estuve y conversaciones entre amigos. Lo que es menos común, es saber cuántas líneas de código tiene el proyecto en el que estamos trabajando.
Si en este momento nos hacemos esa pregunta o se la hacemos a otro miembro del equipo, es posible de que no consigan una respuesta concreta. Si bien es cierto no considero necesario ser 100% precisos, he notado que pocas personas se preocupan de esa métrica, a menos claro, de que haya algún costo asociado.
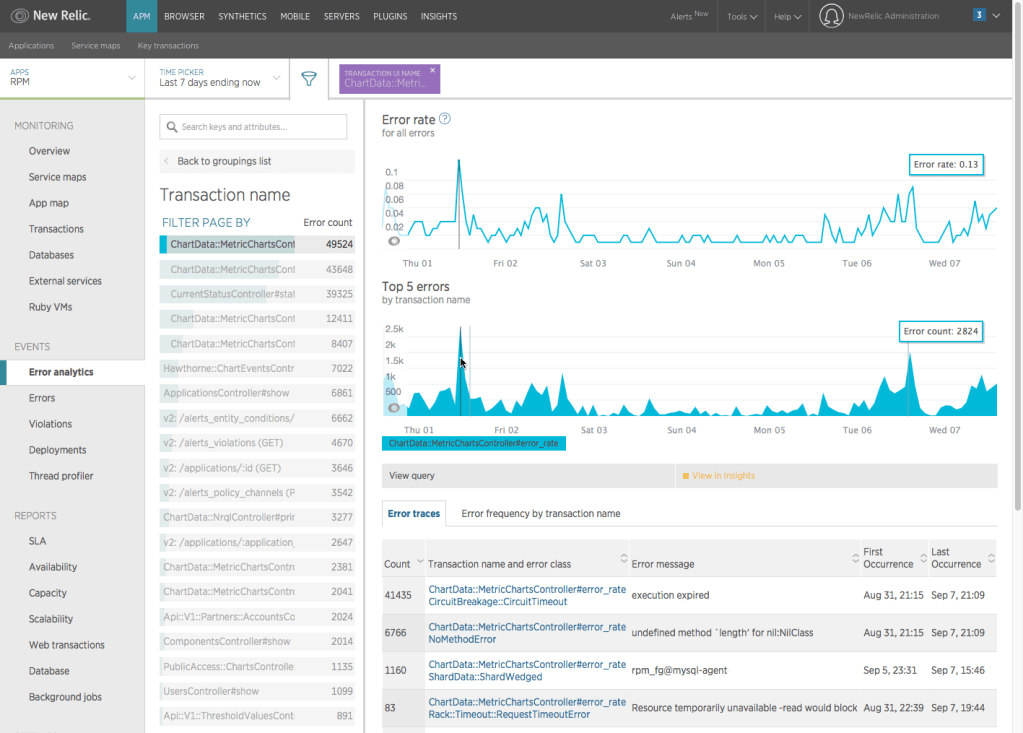
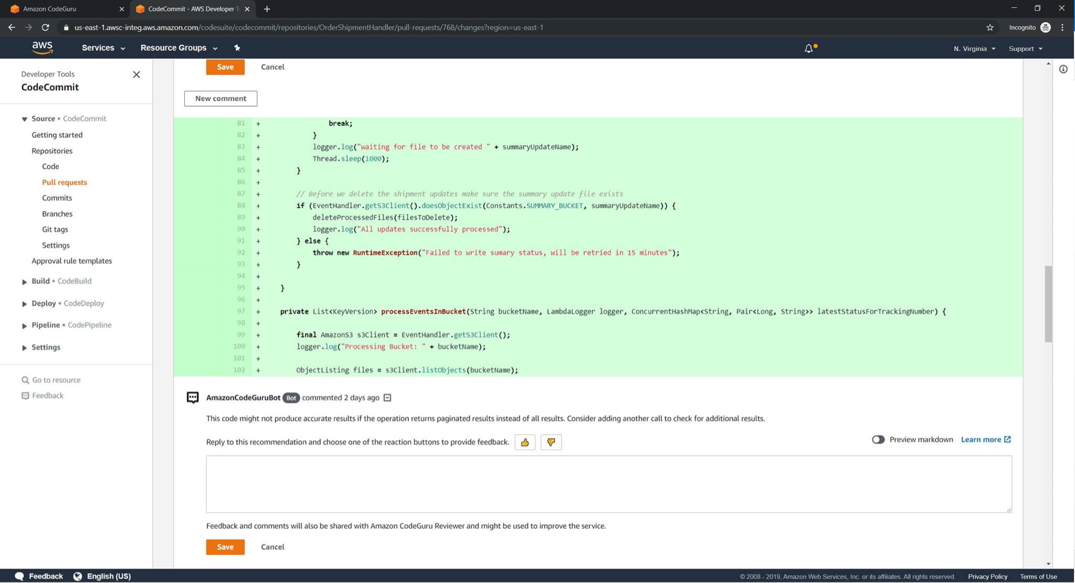
Si no les ha pasado, les comento que casos como este se dan desde hace mucho en proyectos donde se audita código. Sin ir muy lejos, Amazon liberó [CodeGuru], un servicio (aún en preview) que analiza el código fuente. Como es de esperar, el costo está asociado al número de líneas y no es el único producto o servicio que hace este [tipo de trabajos]
¿Qué es lo que regularmente encontraremos?
He participado en proyectos donde el análisis o auditoría de calidad de software era uno de los objetivos más importantes. Muchas veces el costo de servicios adquiridos –u ofrecidos– estaba relacionado al número de líneas de código (o LoC por [Lines of Code]).
En cada trabajo era común confirmar lo encontrado en proyectos anteriores:
- Pocas personas conocían el número de LoC o la importancia de este indicador
- Una práctica conocida –y en algunos casos, aceptada– era “agregar código de ejemplo, ir cambiando y probando pero guardar la versión original por si algo se malograba”
- Muchas veces se mantenían las carpetas de plantillas y ejemplos de las librerías y componentes de terceros que en algunos casos ya no se utilizaban
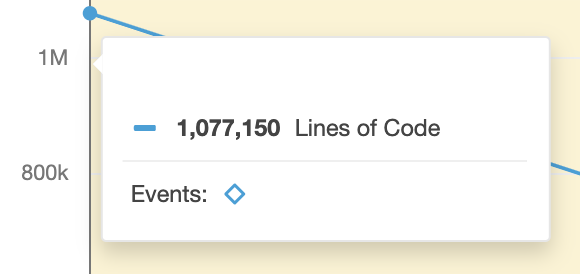
Ya en un caso concreto, estuve en un proyecto donde el desarrollo tenía más de un millón de LoC y estaba seguro de que eso no podía ser posible pues las funcionalidades del sistema no reflejaban dicha realidad.
Sabía que estaba frente a un caso de Código Muerto, pero tenía que demostrarlo.
¿Qué es Código Muerto?
Sin entrar en detalles (pues es posible que encuentren discrepancias y hasta [una canción]), el código muerto o “Dead Code” es aquel que no aporta valor al negocio.
El código muerto se puede clasificar de la siguiente manera:
- Código que no se usa: Muy usual en los proyectos de software, algunas veces no se recuerda su objetivo inicial y por lo general ocurre pues las necesidades van cambiando y el código no se depura adecuadamente luego de cada cambio (mucho cuidado con las frases “es que no hay tiempo” o “lo vemos después”)
- Código que se ejecuta pero que no se usa: Aquí entran los casos como los de variables asignadas o llamadas a funciones cuyo resultado no es utilizado. Esto es nocivo pues además ser código inútil, consume recursos del sistema.

¿Cómo identificar Código Muerto?
Con el paso del tiempo preparé una secuencia de análisis que me sirvió para encontrar casos de código muerto bajo la premisa de que si algo se define en el programa, este debe ser utilizado de manera efectiva. La lista puede parecer obvia, pero ya está demostrado que en tecnología no debemos confiar en las obviedades 🙂
- Variables
- Funciones
- Clases
- Comentarios (sean redundantes o código que fue comentado para ser utilizado “más adelante”)
- Elementos de archivos de configuración (por ejemplo, secciones comentads o que ya no se utilizan)
- Archivos de configuración
- Librerías (componentes de terceros)
- Elementos idénticos (funciones, clases archivos, librerías o carpetas distribuidos en ubicaciones distintas)
- Elementos parecidos (librerías con versiones diferentes, funciones o clases que inicialmente eran una copia de la otra)
- Carpetas y archivos varios que poco a poco quedan relegados hasta el olvido
Un hecho común en todos los casos, es que el código muerto existe debido al temor a perder código o a malograr el sistema construido. Esto tiene relación directa con el desconocimiento de que los gestores de versiones permiten volver al pasado si es que se necesita ver algo que ha sido borrado.
Otra consecuencia es que a más código muerto, más complejo será el entendimiento de nuestro sistema, la mantenibilidad será afectada y a su vez generará dependencias con un programador en particular (a veces pueden ser más personas). Recuerden, el código es de todos los miembros del equipo y mientras menos dependencias, mejor.
¿Qué herramientas debemos usar?
Puede que parezca una broma, pero un elemento muy importante es la inspección visual. A pesar de ello, esta debe pasar a segundo plano pues debemos evitar confiar totalmente de los presentimientos o “literalmente” de puntos de vista.
De acuerdo a esta premisa, lo primero que debemos hacer es trabajar con [herramientas de análisis estático] que nos brinden un enfoque acertado de lo que está ocurriendo.
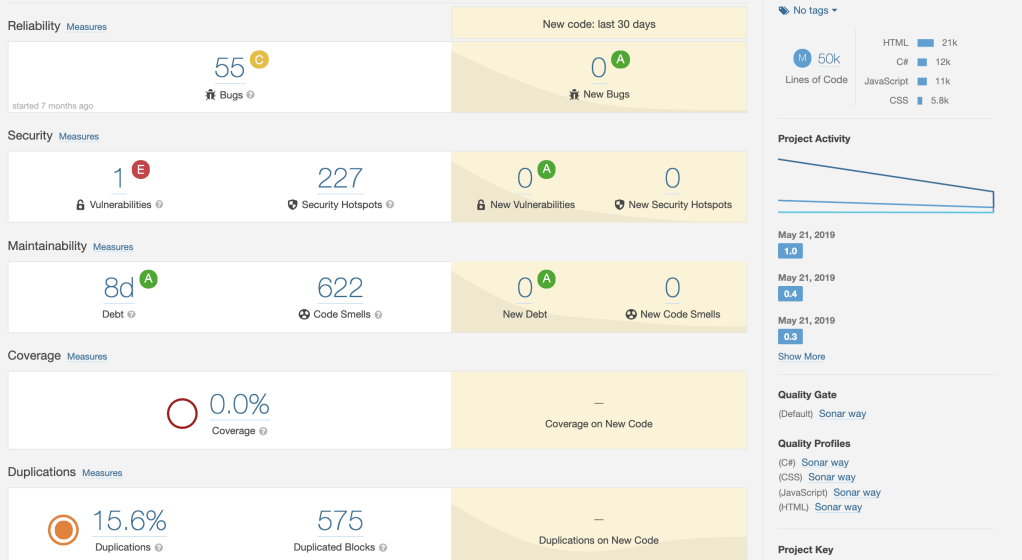
A pesar de ello, hasta el momento no he encontrado una herramienta que brinde un indicador de código muerto bajo un enfoque holístico. Es así que utilizo principalmente [SonarQube] como base del trabajo a realizar.
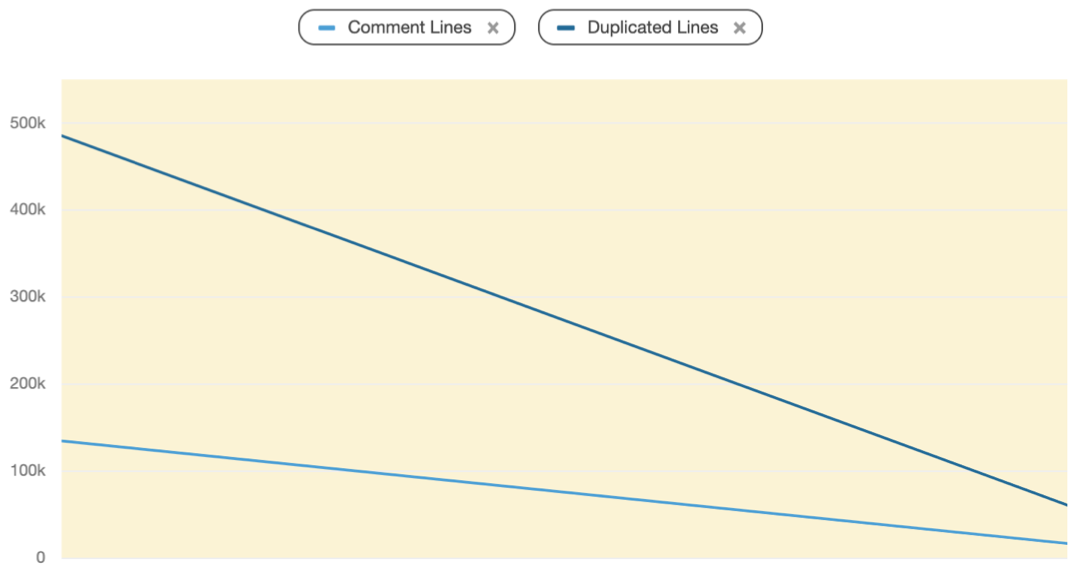
Regresando al caso del millón de LoC, encontré pistas que me ayudaron a confirmar la existencia del temible código muerto.
Si queremos empezar con estas prácticas, algo que nos podría ayudar está incluido en las herramientas del navegador web. Una de las que ha llamado mi atención es la utilizada para analizar la cobertura de los archivos JavaScript y CSS. Esta viene en [Chrome] y no es complicado de usar/entender.
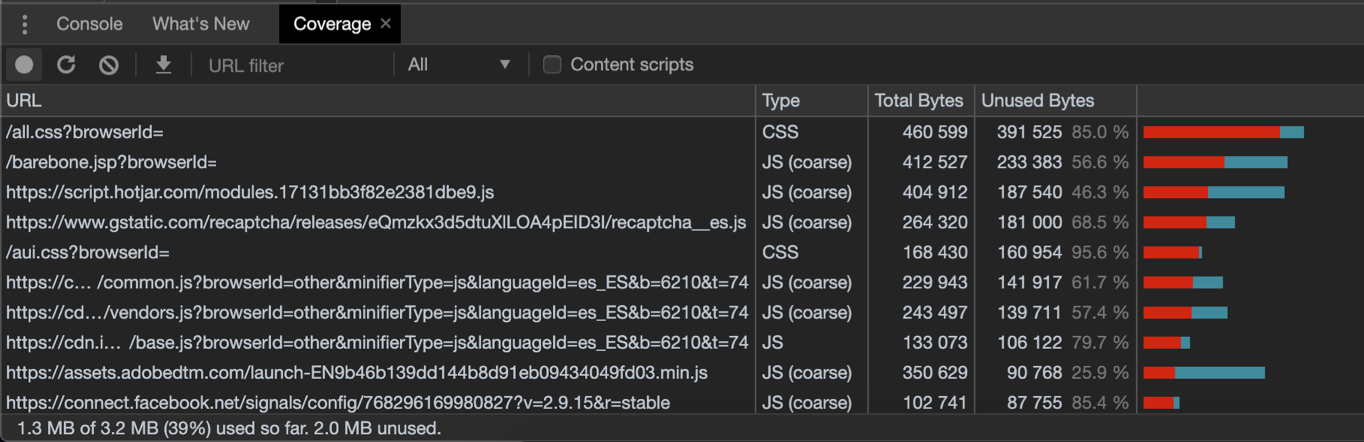
¿Qué conseguí luego de presentar lo encontrado?
El objetivo de mi trabajo en dicho proyecto, fue preparar un informe sobre lo que se estaba construyendo y sobre eso un plan de trabajo para implementar una nueva arquitectura. No me parecía adecuado llegar con una presentación llena de indicadores ni menos señalar responsables (aunque en algunos casos ese ha sido mi trabajo), así que gracias al apoyo y explicaciones que el equipo dio cuando estaba analizando el código, tenía el conocimiento necesario para “limpiarlo”, al menos en casos que parecían obvios o donde veía que complejidad baja o media.
Como este tipo de trabajos me gustan, no paré hasta eliminar 95% del código del sistema. No esperaba llegar a ese número pero más de un millón líneas era código muerto que se podía limpiar fácilmente.
Nada mejor que llegar con un informe que tenga un entregable como ese 🙂
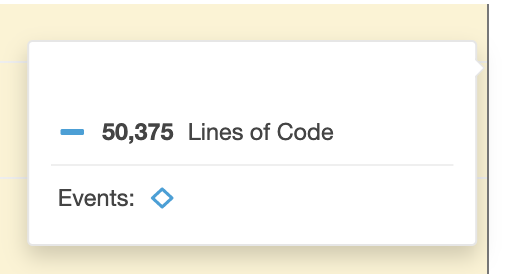
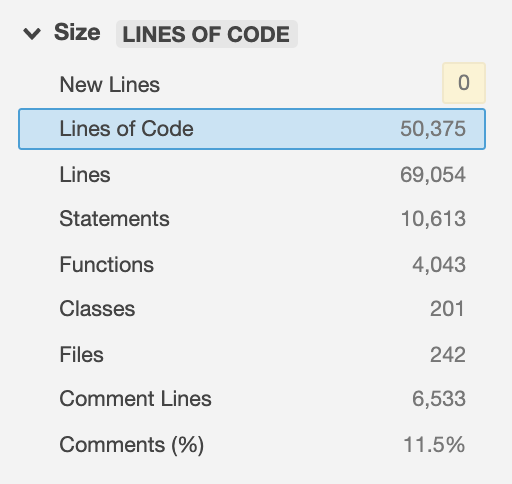
La buena noticias es que el equipo quedó sorprendido. Cuándo me preguntaron cómo lo hice, les comenté que empecé por las obviedades (y ya saben lo que pienso de ellas :)) creo que eso los animó a seguir limpiando (luego de una segunda limpieza el código no superaba las 30 mil LoC)
¿Qué es lo que aprendí?
- Es posible que este tipo de trabajos sea incomprendido al principio, pero se consigue mucho enseñando con el ejemplo. En dicho proyecto tenía que preparar una arquitectura que aproveche lo que ya estaba construido, pero ante las sospechas de código muerto, decidí detenerme un momento y evaluar cómo eliminarlo, primero por mi cuenta y luego con el equipo.
- Lo que he encontrado en muchos casos, es que hay pocas intenciones de refactorización que a veces no se dan por el uso desmedido de frameworks y herramientas. Lo que creo que se debe hacer es sentar una base medible de lo que está sucediendo sin olvidar que lo más se hace en un proyecto de software es la construcción del mismo. Si es así ¿por qué no saber cómo va creciendo nuestro código?
- La automatización de pruebas es muy importante pero esta se debe postergar si hay casos obvios de código muerto, he comprobado que a veces resulta más rápido borrar (sin miedo) que ponermos a programar un caso de prueba.
- Siempre debemos utilizar un gestor de versiones (personalmente prefiero Git sobre GitHub) y tenerlo enlazado a un motor de automatización (como [Jenkins] o [Azure DevOps], ambos me parecen buenos y Azure DevOps es más sencillo de configurar) que ayude a tener visibilidad de la integración continua.
- El equipo de desarrollo pasa a otro nivel de conocimiento, pues además de entender la importancia de prácticas de limpieza de código muerto se abre una nueva puerta hacia la calidad del producto.
- Si la confianza y comunicación son las adecuadas, este tipo de situaciones se convierten en anécdotas del equipo.
¿Cuál fue mi reflexión final?
Antes de refactorizar o hacer lo que sea en el sistema, eliminen el Código Muerto, no teman.
Un abrazo,
Fuente imagen cabecera: [Finding Dead Code]